时间:2025-02-19 11:13 栏目:创新发展明星秀 编辑:投资有道 点击: 771 次
DeepSeek因深度推理模型DeepSeek-R1在全球爆火,表明中国在生成式AI领域的能力进一步加强,全球AI行业格局可能彻底改写。

整个农历春节假期,DeepSeek成为市场“最靓的仔”,掀起了一场大模型变革风暴。
在美国,DeepSeek成为苹果美国应用商店免费APP下载排行榜第一;英伟达在1月27日市值一天蒸发5900亿美元。
而在其他地区,DeepSeek像是奔跑的野马。
在韩国,DeepSeek在生成式AI应用中的用户数量已经排名第二;在印度,DeepSeek受欢迎程度超乎想象,当地下载量占DeepSeek全球总下载量的近16%,成为其最大用户来源。
A股市场同样火热。截至2月7日,美格智能(002881.SZ)股价五连板,每日互动(300766.SZ)股价翻倍,优刻得(688158.SH)、青云科技(688316.SH)连续收获3个“20CM”涨停。
DeepSeek公司网站称,在开源大模型中,DeepSeek-V3的综合能力已经稳居第一,和世界上最先进的闭源模型不分伯仲。
中国AI的爆发
今年中国农历新年最热闹的事,莫过于DeepSeek在全球的突然爆发和对AI行业的颠覆性影响。
1月24日前后,DeepSeek的低成本和开源在美国持续发酵,这不仅引发了市场对美国在人工智能领域领先地位的怀疑,也颠覆了人们对AI高门槛的行业认知。
资本市场立即作出反应,英伟达1月27日的股价暴跌16.86%,市值一天蒸发近5900亿美元,创美股最大单日个股市值缩水纪录。台积电、博通、超微半导体、谷歌、阿斯麦等科技股也紧跟大幅下跌。
同日,在日本东京上市的英伟达主要供应商Advantest Corp.盘中股价暴跌了8.6%。
数据显示,1月25日,DeepSeek在澳大利亚、加拿大、中国、新加坡、美国和英国的苹果应用商店下载排名第一。1月26日,DeepSeek同时在苹果应用商店和谷歌应用商店全球下载排行榜上登顶。到2月初,DeepSeek在全球140个市场的手机应用商店下载排行榜均排在第一。
在韩国,有市场调研机构发布数据显示,DeepSeek以121万用户量,位列韩国1月第四周使用人数第二多的生成式AI应用。
在印度,DeepSeek受到广泛欢迎,其在印度的下载量占DeepSeek全球总下载量的15.6%。
与此同时,AMD选择拥抱Deep Seek,宣布将新的Deep Seek-V3模型集成到I nsti nctMI300X GPU上,与SGLang一起实现最佳性能。
Meta 生成AI小组和基础设施团队学习DeepSeek工作原理,考虑构建基于DeepSeek模型属性重构Meta模型的新技术。
事实上,DeepSeek的全球爆发,只是中国AI技术全面进步的一个样本。
阿里通义千问在1月29日上线了旗舰模型Qwen2.5-Max。阿里方面表示,该模型展现出与DeepSeek-V3、GPT-4和Claude-3.5-Sonnet比肩的性能。在Arena榜单上,其排名甚至超越了DeepSeek-V3。
大模型变革
一年前,DeepSeek几乎还是寂寂无名。
但到了2024年12月,DeepSeek 发布DeepSeek-V3模型,2025年1月20日发布DeepSeek-R1模型,使得DeepSeek迅速蹿红。
DeepSeek称,V3在性能上相当于业界领先的闭源模型GPT-4o与Claude-3.5-Sonnet,优于最好的开源模型Meta的Llama 3;R1模型在一系列任务上实现了与OpenAI o1相当的性能。
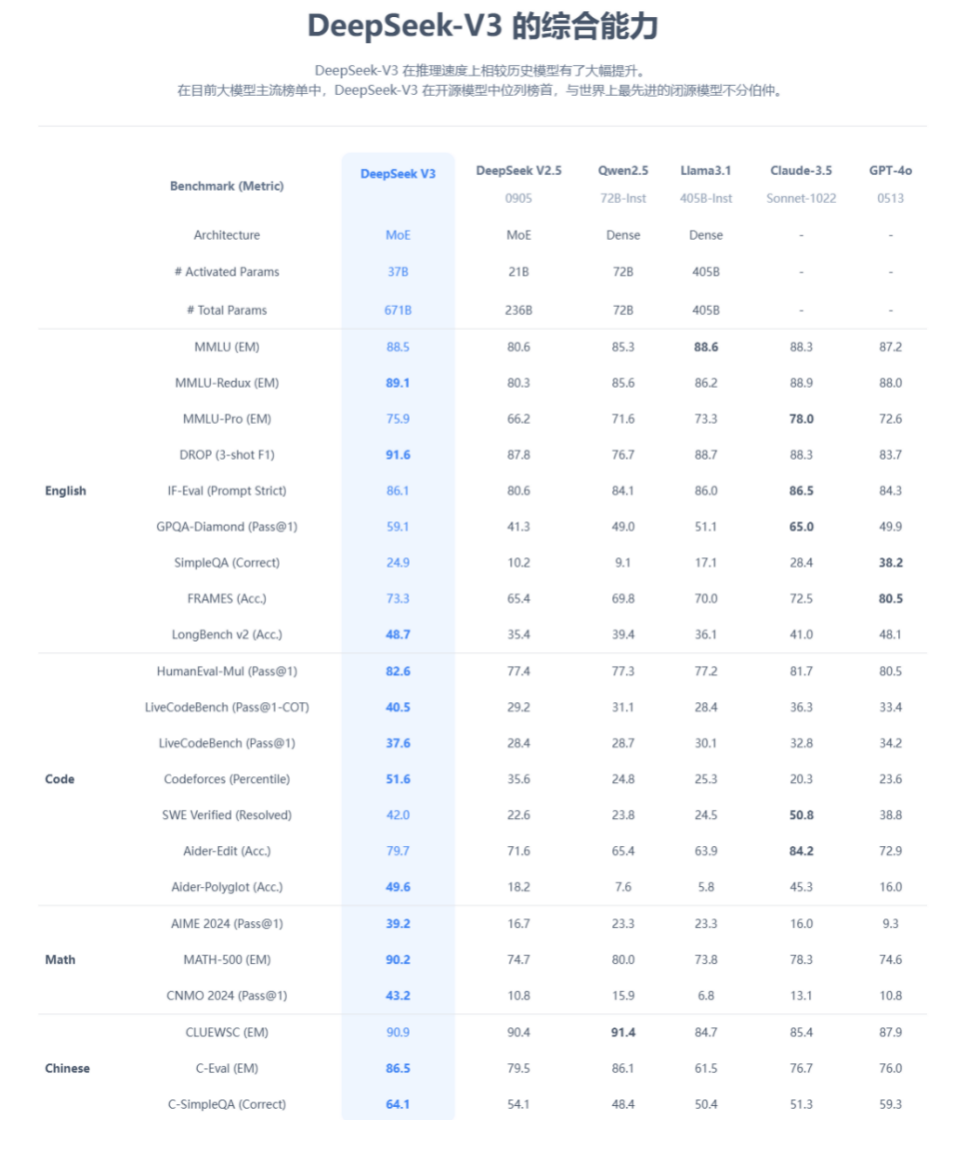
V3是通用AI助手大模型,R1是推理模型,两个模型的特点是高性能和低成本。
据介绍,V3是参数量高达671B的大模型,但预训练阶段仅使用2048块GPU训练了两个月,花费仅557.6万美元。
R1的API服务定价为每百万输入tokens 1元(缓存命中)/4元(缓存未命中),每百万输出tokens 16元。这个收费标准大约是OpenAI o1运行成本的三十分之一。
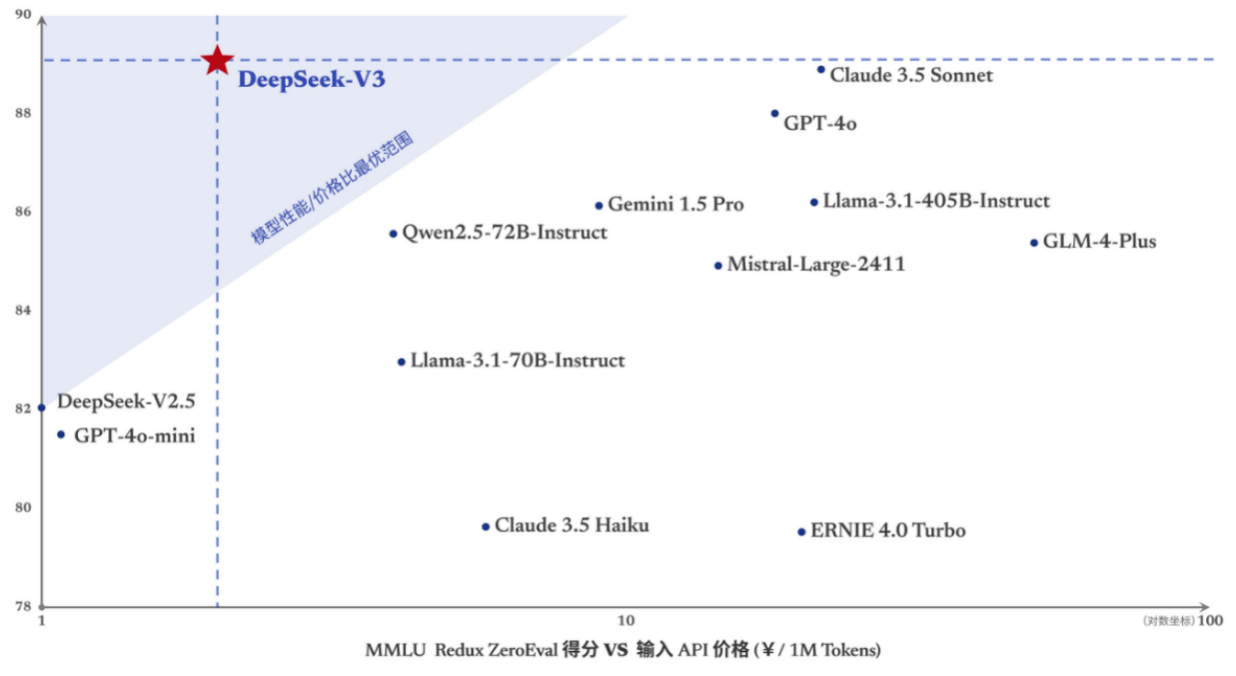
过去,AI产业的投资主要集中在高端算力和数据中心领域,认为AI性能的提升与算力投入呈线性关系,即高端GPU芯片的堆积。业内也将这种大模型路径称为“大力出奇迹”。
而V3采用了优于传统MoE(专家模型)架构的DeepSeek MoE架构,以及优于传统多头注意力(MHA)的DeepSeek MLA(多头潜在注意力)。
DeepSeek的道路是调整改变大模型的基础结构和有效利用有限资源,无需过度依赖大量高性能GPU的堆积。
无疑,它的低成本、高效率AI模型打破了传统AI训练的高成本壁垒,为AI的商业化提供了更多机会。
DeepSeek强大的功能和灵活的应用方式,为AI技术应用于诸如教育、医疗、金融等领域提供了可能,也将进一步拓展AI市场的规模。
英伟达在一份声明中也称,DeepSeek的成果证明了市场对英伟达芯片的需求会更多。
事实上,DeepSeek提供了简单易用的API接口和丰富的开发工具,使得开发者能够更便捷地将AI技术集成到自己的应用中,降低了AI应用开发的门槛,促进了AI技术的普及和应用。
另外,DeepSeek推动大模型变革还体现在用户使用体验上,其在回应用户提问时,会将思维链条完全展示出来,让用户清晰看到它思考问题的逻辑,这激发了大量用户的使用热情。
量化下的“蛋”
众所周知,DeepSeek的背后站着一家量化对冲基金——幻方量化,这和国内AI公司背靠互联网大厂显著不同。
2016年10月,幻方推出首个AI模型,第一次由深度学习算法模型生成的股票仓位上线实盘交易,正式将研发成果投入到实盘交易中。
这也是幻方AI正式使用GPU进行计算。在此之前,主要依靠线性模型和传统机器学习算法,模型计算主要依赖于CPU。
到2017年底,公司几乎所有的量化策略都采用AI模型计算。
此后,幻方不断投资升级AI技术平台。
2019年,幻方AI(杭州幻方人工智能基础研究有限公司)成立,开始自研幻方“萤火一号”AI集群。一年后,搭载1100张GPU、总投资近2亿元的“萤火一号”正式投入使用。
2021年,幻方AI投入10亿元再建“萤火二号”,搭载约1万张英伟达A100 GPU。业内通常认为,1万张英伟达A100 GPU是做自训大模型的算力门槛。据媒体报道,国内拥有超过1万张GPU的企业不超过5家,除幻方之外,其他几家都是头部大厂。这也为后来DeepSeek能够脱颖而出提供了算力基础。
也是2021年,幻方量化的资金达到千亿规模,被称为国内“量化四大天王”之一。
2023年5月,幻方量化宣布成立创新性大模型公司DeepSeek,由知名量化对冲基金高飞资本(High-Flyer)提供资金支持,创始人梁文锋担任CEO。
对于成立DeepSeek,梁文锋有个比喻:“一件激动人心的事,或许不能单纯用钱衡量。就像家里买钢琴,一来买得起,二来是因为有一群急于在上面弹奏乐曲的人。”
这种好奇心和热爱,成为梁文锋组建团队、招聘人才的前提,也是公司的文化。
梁文锋说过,公司招人有条原则是:看能力,而不是看经验。核心技术岗位基本以应届和毕业一两年的人为主。“热爱,扎实的基础能力。其他都没那么重要。”
2024年7月,DeepSeek发布一则顶尖人才招聘广告,据悉当时以百万年薪招聘刚毕业的专业人才曾引发市场热议。
躁动的DeepSeek概念股
在国内,DeepSeek的AI效率革命,引发了A股市场的狂热追捧,相关概念股水涨船高。
截至2025年2月7日,美格智能股价收获五连板,累计大涨61%;每日互动在4个交易日内股价翻倍;优刻得、青云科技连续涨停。
2月7日,并行科技(839493.BJ)录得“30CM”涨停,首都在线(300846.SZ)、品高股份(688227.SH)、万顺新材(300057.SZ)都获得“2 0 CM”涨停。蹭上热点的航锦科技(000818.SZ)已经连续4个交易日涨停,杭钢股份(600126.SH)收获3个涨停。
2月7日晚间,两连板的莲花控股(600186.SH)发布公告称,注意到相关平台将公司股票纳入DeepSeek概念股,公司未直接或间接持有DeepSeek股权。
短短几天时间,A股有数十家公司刊登了与DeepSeek-R1大模型对接的相关公告。
根据Choice金融终端信息,截至2月7日,DeepSeek概念股已经多达65只,近两个交易日,概念指数涨幅达6.74%。
而智度股份(000676.SZ)的股吧里,投资者们为公司有没有参与投资DeepSeek吵翻了天。
有投资者将该问题提交给DeepSeek,DeepSeek回答:2023年公司完成A轮融资,总金额约10亿元。这笔资金主要用于技术研发、团队扩张及市场拓展。投资方主要包括腾讯投资和博裕资本,智度股份跟投。
不过,从目前公开信息看,DeepSeek并没有引进新的股东,大股东依旧是宁波程恩企业管理咨询合伙企业(有限合伙),持股99%,创始人梁文锋间接控股83.2945%。
2月7日,又有传闻称阿里计划以10亿美元投资DeepSeek,估值达100亿美元。但阿里迅速辟谣,此消息不实。
对于资金问题,梁文锋此前曾对媒体表示,幻方作为出资人之一,有充足的研发预算,另外每年有几亿元的捐款预算,之前都是给公益机构,如果需要,也可以做些调整。
公司网站显示,2022年,公司员工“一只平凡的小猪”捐赠各类公益资金1.38亿元。据悉,该员工就是梁文锋。
声明: (本文为投资有道签约作者原创文章,转载请注明出处及作者,否则视为侵权,本刊将追究法律责任)







李总威武
香港高原资本国际金融集团被骗子打
1
sad
[神马]